5. ADMINISTRACION DE PROCESOS 


Uno de los módulos más importantes de un sistema operativo es la de
administrar los procesos y tareas del sistema de cómputo. En esta sección se
revisarán dos temas que componen o conciernen a este módulo: la planificación
del procesador y los problemas de concurrencia.
5.1 Planificación del procesador
La planificación del procesador se
refiere a la manera o técnicas que se usan para decidir cuánto tiempo de
ejecución y cuando se le asignan a cada proceso del sistema. Obviamente, si el
sistema es monousuario y monotarea nohay mucho que decidir, pero en el resto de
los sistemas esto es crucial para el buen funcionamiento del sistema.
5.1.2 Niveles de planificación
En los sistemas de planificación generalmente se identifican tres niveles: el
alto, em medio y el bajo. El nivel alto decide que trabajos (conjunto de
procesos) son candidatos a convertirse en procesos compitiendo por los recursos
del sistema; el nivel intermedio decide que procesos se suspenden o reanudan
para lograr ciertas metas de rendimiento mientras que el planificador de bajo
nivel es el que decide que proceso, de los que ya están listos (y que en algún
momento paso por los otros dos planificadores) es al que le toca ahora estar
ejecutándose en la unidad central de procesamiento. En este trabajo se revisaran
principalmente los planificadores de bajo nivel porque son los que finalmente
eligen al proceso en ejecución.
5.1.3 Objetivos de la planificación
Una estrategia de planificación debe buscar que los procesos obtengan sus
turnos de ejecución apropiadamente, conjuntamente con un buen rendimiento y
minimización de la sobrecarga (overhead) del planificador mismo. En general, se
buscan cinco objetivos principales:
- Justicia o Imparcialidad: Todos los procesos son tratados de la
misma forma, y en algún momento obtienen su turno de ejecución o intervalos de
tiempo de ejecución hasta su terminación exitosa.
- Maximizar la Producción: El sistema debe de finalizar el mayor
numero de procesos en por unidad de tiempo.
- Maximizar el Tiempo de Respuesta: Cada usuario o proceso debe
observar que el sistema les responde consistentemente a sus requerimientos.
- Evitar el aplazamiento indefinido: Los procesos deben terminar en
un plazo finito de tiempo.
- El sistema debe ser predecible: Ante cargas de trabajo ligeras el
sistema debe responder rápido y con cargas pesadas debe ir degradándose
paulatinamente. Otro punto de vista de esto es que si se ejecuta el mismo
proceso en cargas similares de todo el sistema, la respuesta en todos los
casos debe ser similar.
5.1.4 Características a considerar de los procesos
No todos los equipos de cómputo procesan el mismo tipo de trabajos, y un
algoritmo de planificación que en un sistema funciona excelente puede dar un
rendimiento pésimo en otro cuyos procesos tienen características diferentes.
Estas características pueden ser:
- Cantidad de Entrada/Salida: Existen procesos que realizan una gran
cantidad de operaciones de entrada y salida (aplicaciones de bases de datos,
por ejemplo).
- Cantidad de Uso de CPU: Existen procesos que no realizan muchas
operaciones de entrada y salida, sino que usan intensivamente la unidad
central de procesamiento. Por ejemplo, operaciones con matrices.
- Procesos de Lote o Interactivos: Un proceso de lote es más
eficiente en cuanto a la lectura de datos, ya que generalmente lo hace de
archivos, mientras que un programa interactivo espera mucho tiempo (no es lo
mismo el tiempo de lectura de un archivo que la velocidad en que una persona
teclea datos) por las respuestas de los usuarios.
- Procesos en Tiempo Real: Si los procesos deben dar respuesta en
tiempo real se requiere que tengan prioridad para los turnos de ejecución.
- Longevidad de los Procesos: Existen procesos que tipicamente
requeriran varias horas para finalizar su labor, mientras que existen otros
que solonecesitan algunos segundos.
5.1.5 Planificación apropiativa o no apropiativa (preemptive or not
preemptive)
La planificación apropiativa es aquella en la cual, una vez que a un proceso
le toca su turno de ejecución ya no puede ser suspendido, ya no se le puede
arrebatar la unidad central de procesamiento. Este esquema puede ser peligroso,
ya que si el proceso contiene accidental o deliberadamente ciclos infinitos, el
resto de los procesos pueden quedar aplazados indefinidamente. Una planificación
no apropiativa es aquella en que existe un reloj que lanza interrupciones
periodicas en las cuales el planificador toma el control y se decide si el mismo
proceso seguirá ejecutándose o se le da su turno a otro proceso. Este mismo
reloj puede servir para lanzar procesos manejados por el reloj del sistema. Por
ejemplo en los sistemas UNIX existen los 'cronjobs' y 'atjobs', los cuales se
programan en base a la hora, minuto, día del mes, día de la semana y día del
año.
En una planificación no apropiativa, un trabajo muy grande aplaza mucho a uno
pequeño, y si entra un proceso de alta prioridad esté también debe esperar a que
termine el proceso actual en ejecución.
5.1.6 Asignación del turno de ejecución
Los algoritmos de la capa baja para asignar el turno de ejecución se
describen a continuación:
5.2 Problemas de Concurrencia
En los sistemas de tiempo compartido
(aquellos con varios usuarios, procesos, tareas, trabajos que reparten el uso de
CPU entre estos) se presentan muchos problemas debido a que los procesos
compiten por los recursos del sistema. Imagine que un proceso está escribiendo
en la unidad de cinta y se le termina su turno de ejecución e inmediatamente
después el proceso elegido para ejecutarse comienza a escribir sobre la misma
cinta. El resultado es una cinta cuyo contenido es un desastre de datos
mezclados. Así como la cinta, existen una multitud de recursos cuyo acceso debe
der controlado para evitar los problemas de la concurrencia.
El sistema operativo debe ofrecer mecanismos para sincronizar la ejecución de
procesos: semáforos, envío de mensajes, 'pipes', etc. Los semáforos son rutinas
de software (que en su nivel más interno se auxilian del hardware) para lograr
exclusión mutua en el uso de recursos. Para entender este y otros mecanismos es
importante entender los problemas generales de concurrencia, los cuales se
describen enseguida.
- Condiciones de Carrera o Competencia: La condición de carrera (race
condition) ocurre cuando dos o más procesos accesan un recurso compartido sin
control, de manera que el resultado combinado de este acceso depende del orden
de llegada. Suponga, por ejemplo, que dos clientes de un banco realizan cada
uno una operación en cajeros diferentes al mismo tiempo.
El usuario A quiere hacer un depósito. El B un retiro. El usuario A
comienza la transacción y lee su saldo que es 1000. En ese momento pierde su
turno de ejecución (y su saldo queda como 1000) y el usuario B inicia el
retiro: lee el saldo que es 1000, retira 200 y almacena el nuevo saldo que es
800 y termina. El turno de ejecución regresa al usuario A el cual hace su
depósito de 100, quedando saldo = saldo + 100 = 1000 + 100 = 1100. Como se ve,
el retiro se perdió y eso le encanta al usuario A y B, pero al banquero no le
convino esta transacción. El error pudo ser al revés, quedando el saldo final
en 800.
- Postergación o Aplazamiento Indefinido(a): Esto se mencionó en el
apartado anterior y consiste en el hecho de que uno o varios procesos nunca
reciban el suficiente tiempo de ejecución para terminar su tarea. Por ejemplo,
que un proceso ocupe un recurso y lo marque como 'ocupado' y que termine sin
marcarlo como 'desocupado'. Si algún otro proceso pide ese recurso, lo verá
'ocupado' y esperará indefinidamente a que se 'desocupe'.
- Condición de Espera Circular: Esto ocurre cuando dos o más procesos
forman una cadena de espera que los involucra a todos. Por ejemplo, suponga
que el proceso A tiene asignado el recurso 'cinta' y el proceso B tiene
asignado el recurso 'disco'. En ese momento al proceso A se le ocurre pedir el
recurso 'disco' y al proceso B el recurso 'cinta'. Ahi se forma una espera
circular entre esos dos procesos que se puede evitar quitándole a la fuerza un
recurso a cualquiera de los dos procesos.
- Condición de No Apropiación: Esta condición no resulta precisamente
de la concurrencia, pero juega un papel importante en este ambiente. Esta
condición especifica que si un proceso tiene asignado un recurso, dicho
recurso no puede arrebatársele por ningún motivo, y estará disponible hasta
que el proceso lo 'suelte' por su voluntad.
- Condición de Espera Ocupada: Esta condición consiste en que un
proceso pide un recurso que ya está asignado a otro proceso y la condición de
no apropiación se debe cumplir. Entonces el proceso estará gastando el resto
de su time slice checando si el recurso fue liberado. Es decir, desperdicia su
tiempo de ejecución en esperar. La solución más común a este problema consiste
en que el sistema operativo se dé cuenta de esta situación y mande a una cola
de espera al proceso, otorgándole inmediatamente el turno de ejecución a otro
proceso.
- Condición de Exclusión Mutua: Cuando un proceso usa un recurso del
sistema realiza una serie de operaciones sobre el recurso y después lo deja de
usar. A la sección de código que usa ese recurso se le llama 'región crítica'.
La condición de exclusión mutua establece que solamente se permite a un
proceso estar dentro de la misma región crítica. Esto es, que en cualquier
momento solamente un proceso puede usar un recurso a la vez. Para lograr la
exclusión mutua se ideo también el concepto de 'región crítica'. Para logar la
exclusión mutua generalmente se usan algunas técnicas para lograr entrar a la
región crítica: semáforos, monitores, el algoritmo de Dekker y Peterson, los
'candados'. Para ver una descripción de estos algoritmos consulte [Deitel93]
[Tan92].
- Condición de Ocupar y Esperar un Recurso: Consiste en que un
proceso pide un recurso y se le asigna. Antes de soltarlo, pide otro recurso
que otro proceso ya tiene asignado.
Los problemas descritos son todos importantes para el sistema
operativo, ya que debe ser capaz de prevenir o corregirlos. Tal vez el problema
más serio que se puede presentar en un ambiente de concurrencia es el 'abrazo
mortal', también llamado 'trabazón' y en inglés deadlock. El deadlock es una
condición que ningún sistema o conjunto de procesos quisiera exhibir, ya que
consiste en que se presentan al mismo tiempo cuatro condiciones necesarias: La
condición de no apropiación, la condición de espera circular, la condición de
exclusión mutua y la condición de ocupar y esperar un recurso. Ante esto, si el
deadlock involucra a todos los procesos del sistema, el sistema ya no podrá
hacer algo productivo. Si el deadlock involucra algunos procesos, éstos quedarán
congelados para siempre.
En el área de la informática, el problema del deadlock ha provocado y
producido una serie de estudios y técnicas muy útiles, ya que éste puede surgir
en una sola máquina o como consecuencia de compartir recursos en una red.
En el área de las bases de datos y sistemas distribuidos han surgido técnicas
como el 'two phase locking' y el 'two phase commit' que van más allá de este
trabajo. Sin embargo, el interés principal sobre este problema se centra en
generar técnicas para detectar, prevenir o corregir el deadlock.
Las técnicas para prevenir el deadlock consisten en proveer mecanismos para
evitar que se presente una o varias de las cuatro condiciones necesarias del
deadlock. Algunas de ellas son:
- Asignar recursos en orden lineal: Esto significa que todos los
recursos están etiquetados con un valor diferente y los procesos solo pueden
hacer peticiones de recursos 'hacia adelante'. Esto es, que si un proceso
tiene el recurso con etiqueta '5' no puede pedir recursos cuya etiqueta sea
menor que '5'. Con esto se evita la condición de ocupar y esperar un recurso.
- Asignar todo o nada: Este mecanismo consiste en que el proceso pida
todos los recursos que va a necesitar de una vez y el sistema se los da
solamente si puede dárselos todos, si no, no le da nada y lo bloquea.
- Algoritmo del banquero: Este algoritmo usa una tabla de recursos
para saber cuántos recursos tiene de todo tipo. También requiere que los
procesos informen del máximo de recursos que va a usar de cada tipo. Cuando un
proceso pide un recurso, el algoritmo verifica si asignándole ese recurso
todavía le quedan otros del mismo tipo para que alguno de los procesos en el
sistema todavía se le pueda dar hasta su máximo. Si la respuesta es
afirmativa, el sistema se dice que está en 'estado seguro' y se otorga el
recurso. Si la respuesta es negativa, se dice que el sistema está en estado
inseguro y se hace esperar a ese proceso.
Para detectar un deadlock, se puede usar el mismo algoritmo del banquero, que
aunque no dice que hay un deadlock, sí dice cuándo se está en estado inseguro
que es la antesala del deadlock. Sin embargo, para detectar el deadlock se
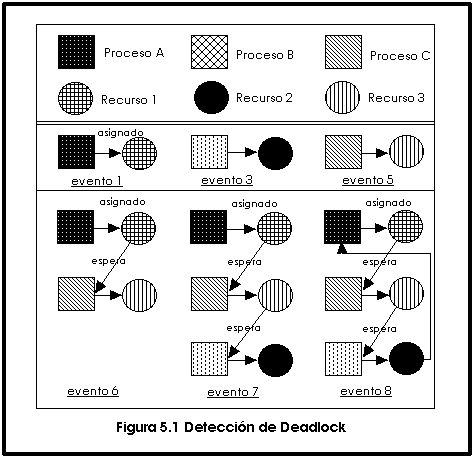
pueden usar las 'gráficas de recursos'. En ellas se pueden usar cuadrados para
indicar procesos y círculos para los recursos, y flechas para indicar si un
recurso ya está asignado a un proceso o si un proceso está esperando un recurso.
El deadlock es detectado cuando se puede hacer un viaje de ida y vuelta desde un
proceso o recurso. Por ejemplo, suponga los siguientes eventos:
evento 1: Proceso A pide recurso 1 y se le asigna.
evento 2: Proceso A termina su time slice.
evento 3: Proceso B pide recurso 2 y se le asigna.
evento 4: Proceso B termina su time slice.
evento 5: Proceso C pide recurso 3 y se le asigna.
evento 6: Proceso C pide recurso 1 y como lo está ocupando el proceso A,
espera.
evento 7: Proceso B pide recurso 3 y se bloquea porque lo ocupa el proceso C.
evento 8: Proceso A pide recurso 2 y se bloquea porque lo ocupa el proceso B.
En la figura 5.1 se observa como el 'resource graph' fue evolucionando hasta
que se presentó el deadlock, el cual significa que se puede viajar por las
flechas desde un proceso o recurso hasta regresar al punto de partida. En el
deadlock están involucrados los procesos A,B y C.
Una vez que un deadlock se detecta, es obvio que el sistema está en problemas
y lo único que resta por hacer es una de dos cosas: tener algún mecanismo de
suspensión o reanudación [Deitel93] que permita copiar todo el contexto de un
proceso incluyendo valores de memoria y aspecto de los periféricos que esté
usando para reanudarlo otro día, o simplemente eliminar un proceso o arrebatarle
el recurso, causando para ese proceso la pérdida de datos y tiempo.
Indice
| Anterior
| Siguiente